🧠 Needle-in-the-Haystack: Testing LLMs with a Complex Reasoning Task
This repository accompanies the publication:
Needle-in-the-Haystack: Testing LLMs with a Complex Reasoning Task
Thomas Schuster, Marian Lambert, Nico Döring, Julius Trögele
XPACE GmbH & Pforzheim University
📌 Overview
This project explores how well large language models (LLMs) can reason over long input contexts in a realistic legal-tech scenario. While many models perform well on traditional “needle-in-the-haystack” (NIH) retrieval tests, our benchmark introduces a complex reasoning task inspired by real-world consumer protection use cases.
LLMs are tasked with determining whether a product description violates a given cease-and-desist declaration — requiring not just retrieval, but semantic understanding and structured reasoning.
🧪 Experimental Setup
🔍 Task
The core task is compliance classification:
- Input: Cease-and-desist declaration + long product description (German)
- Output: JSON object including:
- Violation status (
true/false) - Confidence score
- Extracted relevant passages
- Explanation of reasoning
- Violation status (
Models are prompted with:
- Chain-of-thought reasoning instructions
- Four few-shot examples
- A structured JSON output schema
🧾 Dataset
The dataset contains:
- 411 original labeled pairs (cease-and-desist + product description)
- Augmented into 20,961 samples across:
- 10 context lengths:
64to32,768tokens - 5 needle positions:
0%, 25%, 50%, 75%, 100% - 1 base (no filler) variant
- 10 context lengths:
Each product description is embedded within a synthetic, legally-neutral filler document generated using GPT-4o.
🤖 Models Tested
| Model Name | Size | Context Limit | License |
|---|---|---|---|
| LLaMa 3.1 | 70B | 128k | Open weights |
| LLaMa 3.1 | 8B | 128k | Open weights |
| Nemotron | 70B | 128k | Open weights |
| Qwen 2.5 | 72B | 131k | Open weights |
| Mixtral | 8x22B | 65k | Open weights |
| Mistral Large 2 | 123B | 128k | Open weights (EETQ quantized) |
| GPT-4o Mini | - | 128k | Proprietary |
Models were run using HuggingFace Text Generation Inference on a DGX A100 node (4× A100 GPUs, 80GB VRAM each).
📊 Results
Results are presented as heatmaps (and as tabular data in this repository) of classification accuracy across:
- Context lengths (
64to32,768tokens) - Needle insertion positions (
0%to100%)
Results by Model
LLaMa 3.1 70B
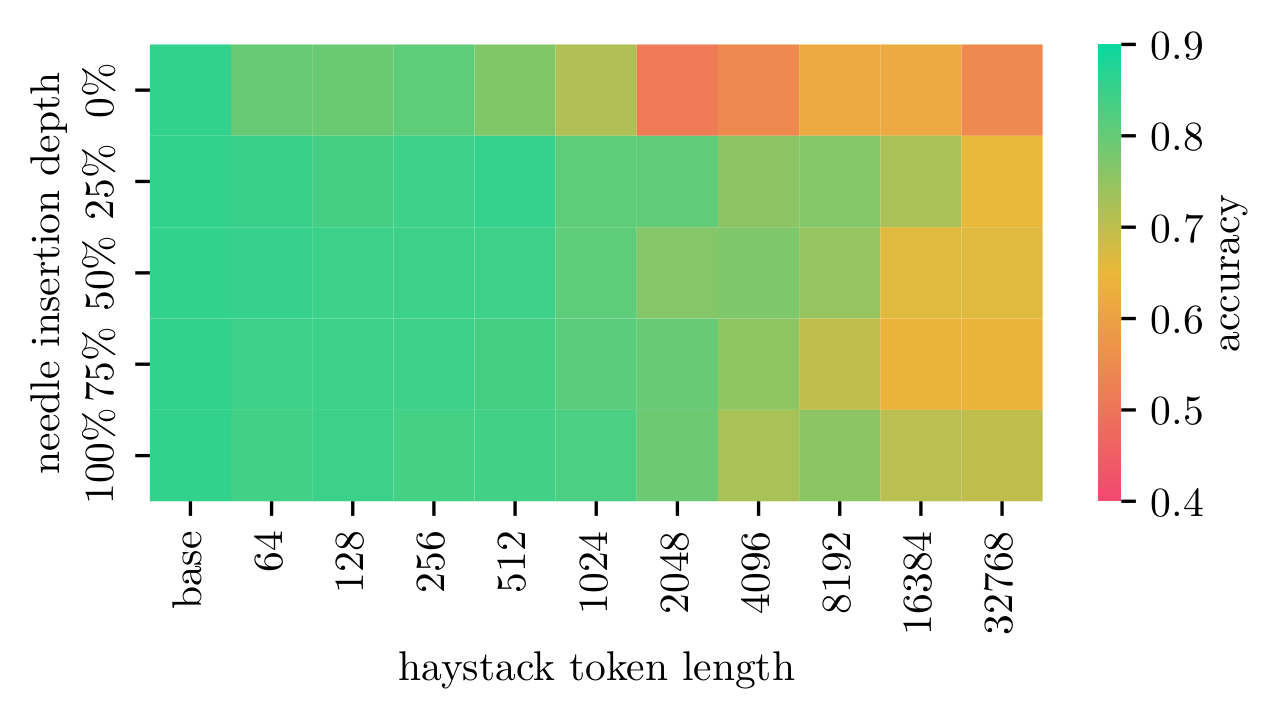 Detailed results for LLaMa 3.1 70B
Detailed results for LLaMa 3.1 70B
LLaMa 3.1 8B
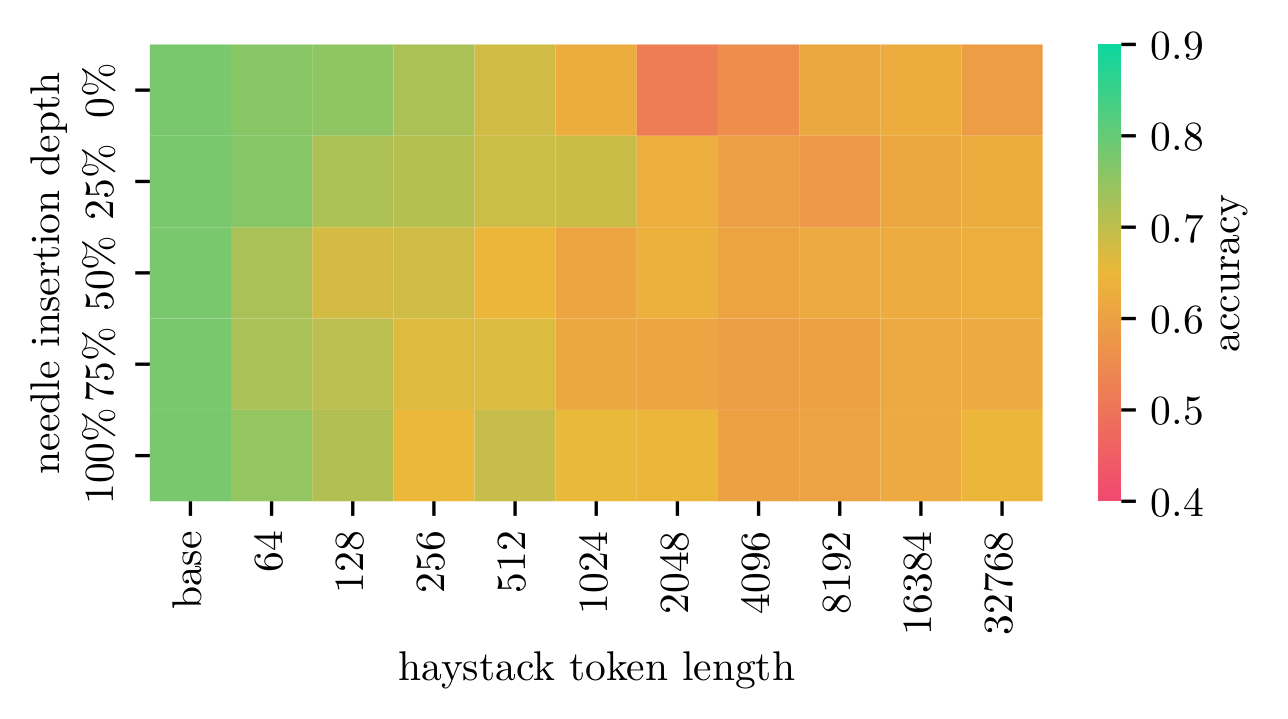 Detailed results for LLaMa 3.1 8B
Detailed results for LLaMa 3.1 8B
Nemotron 70B
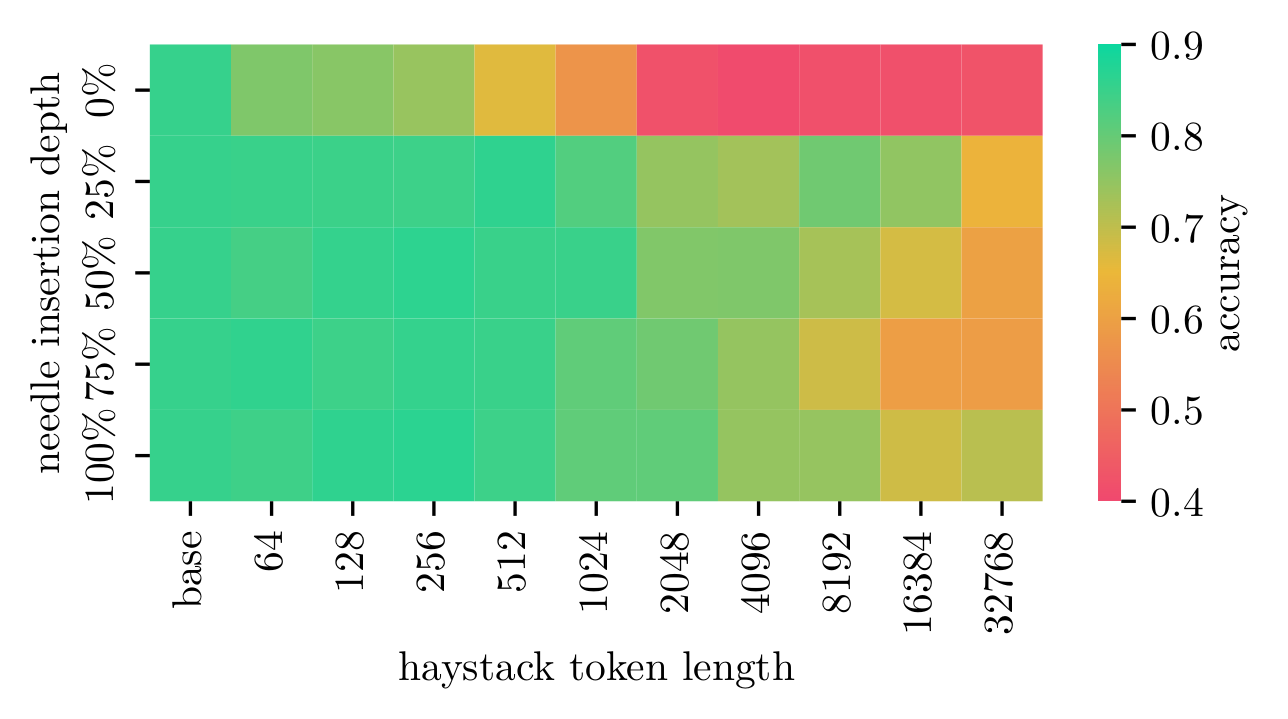 Detailed results for Nemotron 70B
Detailed results for Nemotron 70B
Qwen 2.5 72B
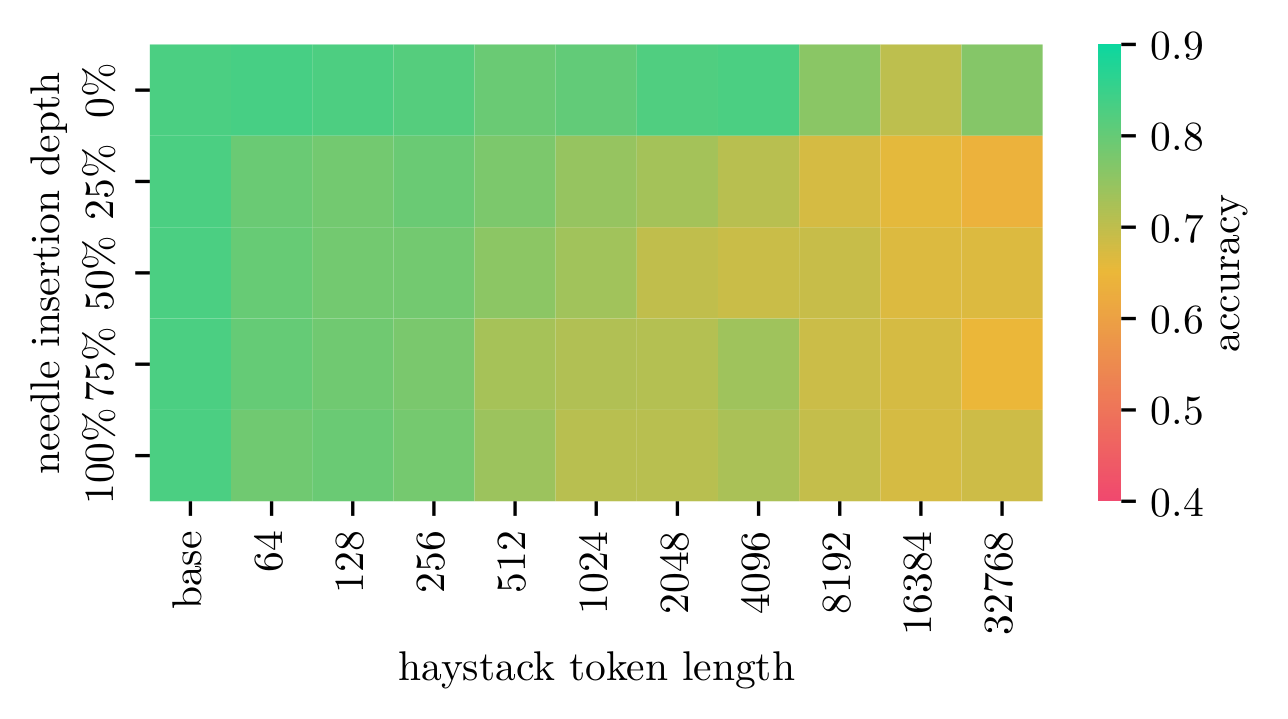 Detailed results for Qwen 2.5 72B
Detailed results for Qwen 2.5 72B
Mixtral 8x22B
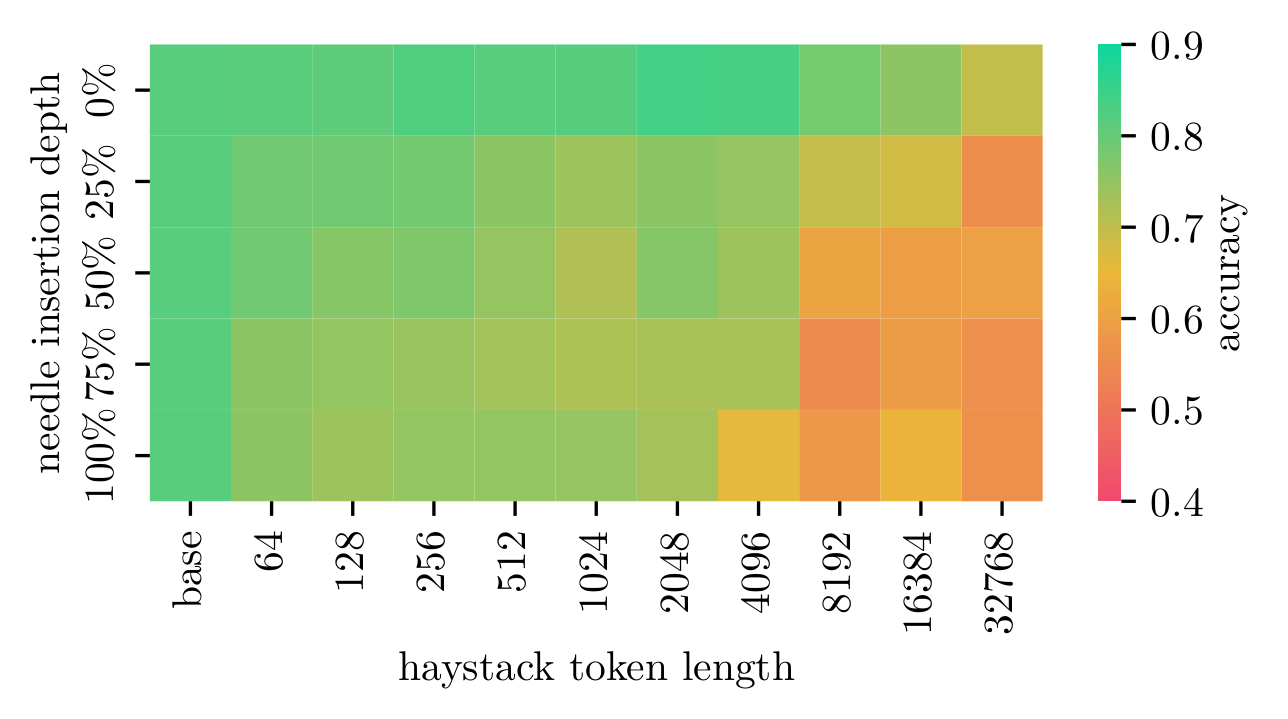 Detailed results for Mixtral 8x22B
Detailed results for Mixtral 8x22B
Mistral Large 2 123B
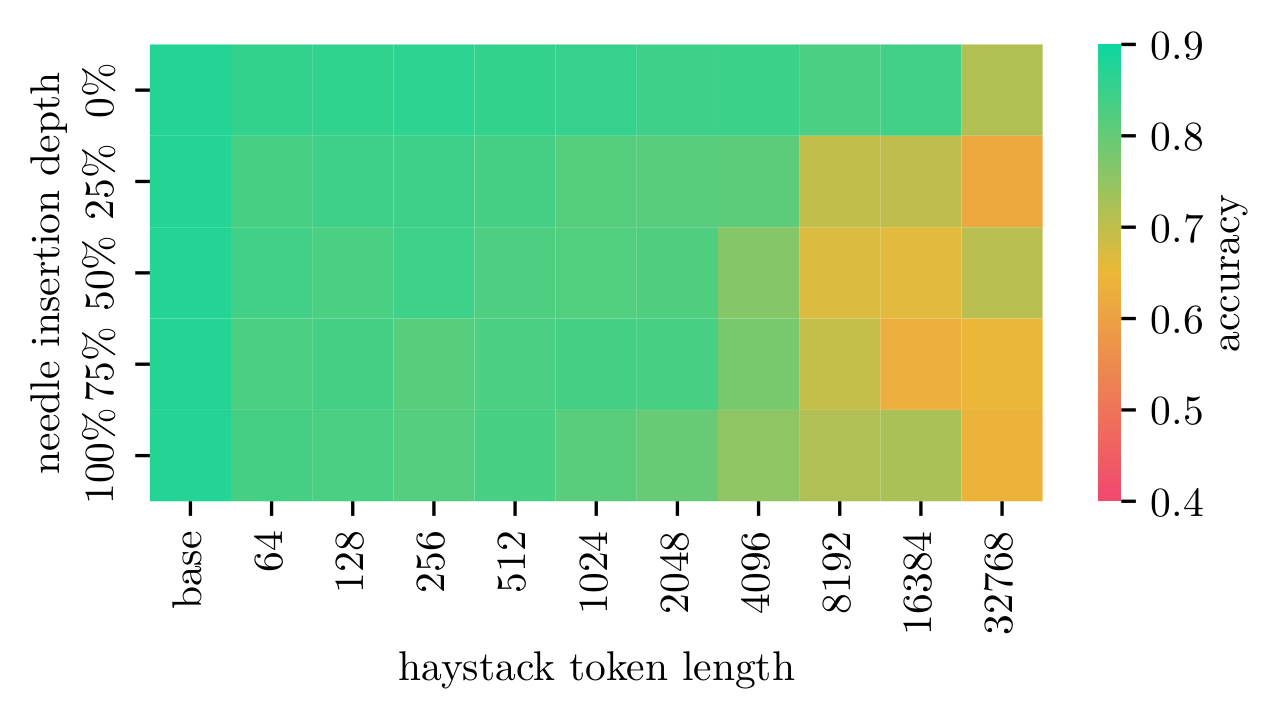 Detailed results for Mistral Large 2 123B
Detailed results for Mistral Large 2 123B
GPT-4o Mini
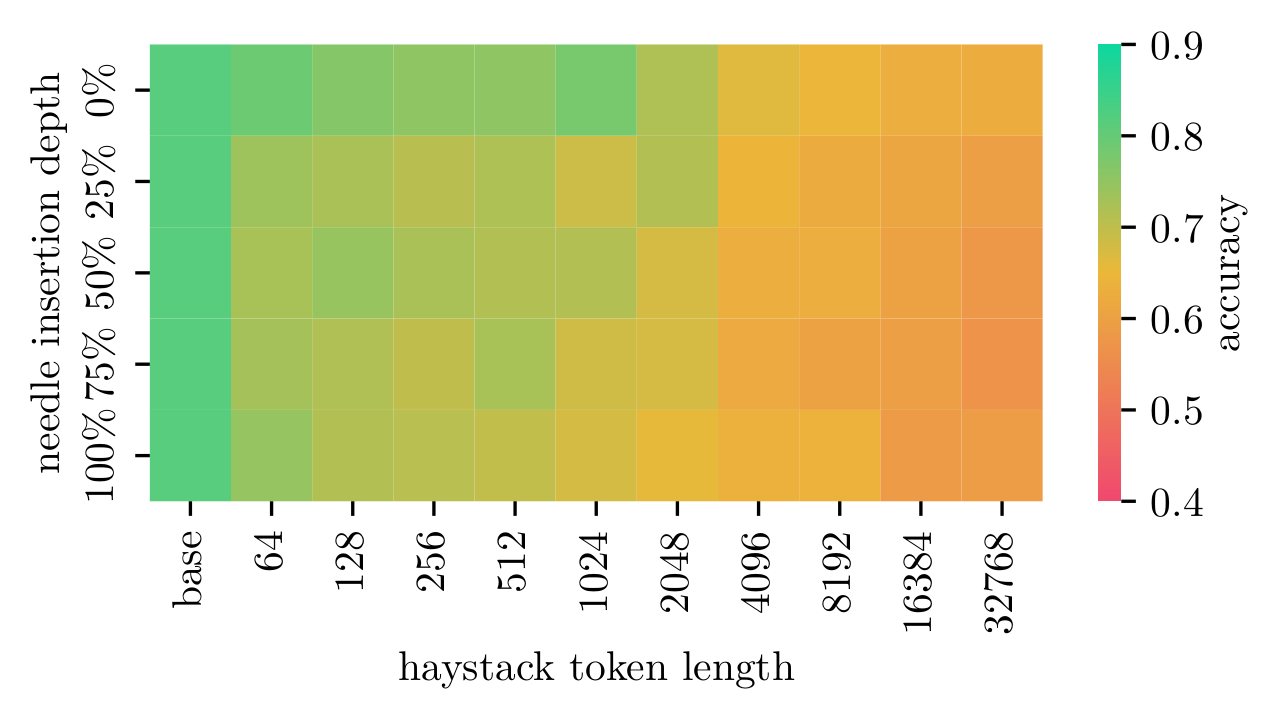 Detailed results for GPT-4o Mini
Detailed results for GPT-4o Mini
Key Findings
- Accuracy drops with increasing context, especially at 2k+ tokens.
- Most models struggle with needles at the start/middle of long contexts.
- Mistral Large 2 showed the most robust and consistent performance.
- Open-weight models showed varying sensitivity to insertion depth.
For full details, see the visualizations and discussion in Section 4 of the paper.
📁 Repository Structure
.
├── results/
│ ├── llama3.1-70.md # Results for LLaMa 3.1 70B
│ ├── llama3.1-8.md # Results for LLaMa 3.1 8B
│ ├── nemotron-70.md # Results for Nemotron 70B
│ ├── qwen2.5-72.md # Results for Qwen 2.5 72B
│ ├── mixtral-8x22.md # Results for Mixtral 8x22B
│ ├── mistral-large-2.md # Results for Mistral Large 2 123B
│ ├── gpt-4o-mini.md # Results for GPT-4o Mini
│ └── all_models_results.csv # Comprehensive results data for all models
└── README.md # This file
📜 Citation
If you use this dataset or results in your research, please cite:
@inproceedings{schusterNeedleintheHaystackTestingLLMs2025a,
title = {Needle-in-the-Haystack Testing LLMs with a Complex Reasoning Task},
booktitle = {Engineering Applications of Neural Networks},
author = {Schuster, Thomas and Lambert, Marian and Döring, Nico and Trögele, Julius},
editor = {Iliadis, Lazaros and Maglogiannis, Ilias and Kyriacou, Efthyvoulos and Jayne, Chrisina},
date = {2025},
pages = {254--266},
publisher = {Springer Nature Switzerland},
location = {Cham},
doi = {10.1007/978-3-031-96196-0_19},
abstract = {Large Language Models (LLMs) are celebrated for their extended context capabilities, but questions remain regarding their effective use of this capacity. While ‘needle-in-the-haystack’ tests have become standard benchmarks for in-context retrieval performance, they often fall short in reflecting the challenges of real-world applications. This study evaluates the performance of six open-weight LLMs and one proprietary model on a complex reasoning task. The task is designed to locate relevant passages within variable-length product descriptions and assess their compliance with a specified cease-and-desist declaration. We tested context lengths ranging from \$\$\{ 64 \textbackslash times 2\textasciicircum n \textbackslash mid n = 0, 1, 2, \textbackslash dots , 9 \}\$\$64×2n∣n=0,1,2,⋯,9across needle document depths of 0\%, 25\%, 50\%, 75\%, and 100\%. Our findings show that model performance tends to decline with longer contexts, with variation across models. Often, performance was poorer when the key information appeared early or in the middle of the input. Some models maintained more consistent performance, while others revealed significant degradation. These results suggest the need for improved LLM architectures to handle extended contexts and complex reasoning tasks effectively.},
isbn = {978-3-031-96196-0},
langid = {english}
}
🧑💼 Authors
- Thomas Schuster — Pforzheim University
- Marian Lambert, Nico Döring, Julius Trögele — XPACE GmbH
For questions or collaborations, contact us at info@xpace.de